Yapay Sinir Ağları¶
Bu yazıyı ve kodları hazırlarken, Michael Nielson'ın açık kaynak Neural Networks and Deep Learning adlı kitabından yararlandım.
Numpy hatırlayalım¶
import random
import numpy as np

e = np.array([[1,1],
[2,2],
[3,3,]])
f = np.array([[1],
[0]])
print(np.shape(e))
print(np.shape(f))
print(e.dot(f))
print(e,"\n")
print(e.T,"\n")
for a, b in zip(e, e.T):
print(a,b)
dVeri = np.array([1,2,3])
def dFonk():
dVeri = 2 * dVeri
print(dVeri)
dVeri = 2 * dVeri
print(dVeri)
A = [1,3,5,7]
B = ["a","b","x","y"]
for a,b in zip(A,B):
print(a,b)
Yardimci Fonksiyonlar¶
Sıgmoid fonksiyonu bir nöronun gelen toplam girdiyi, 0 ile 1 arasında bie çıktı değerine dönüştürür. Bu fonksiyonun türevi, kendisi ile 1den cıkarılmış halinin çarpınıma eşittir.
#### Yardimci Fonksiyonlar
def sigmoid(z):
return 1.0/(1.0+np.exp(-z))
def sigmoid_turevi(z):
return sigmoid(z)*(1-sigmoid(z))
Ağı oluşturalım¶
Her bir katmanda kaç sinir hücresi olacağını bir listeden alarak, ağı oluşturan bir fonksiyon yazalım.
def ag(katmanlar):
b = [np.random.randn(k, 1) for k in katmanlar[1:]] # bias degerleri (ilk katman haric)
W = [np.random.randn(k2, k1) for k1, k2 in zip(katmanlar[:-1],katmanlar[1:])]
return W, b
Örnek bir ağ¶
katmanlar = [3, 4, 2]
agirlik, bias = ag(katmanlar)
print("agirlik :")
for w in agirlik:
print(w, "\n")
print("bias :")
for b in bias:
print(b, "\n")
İleri Besleme¶
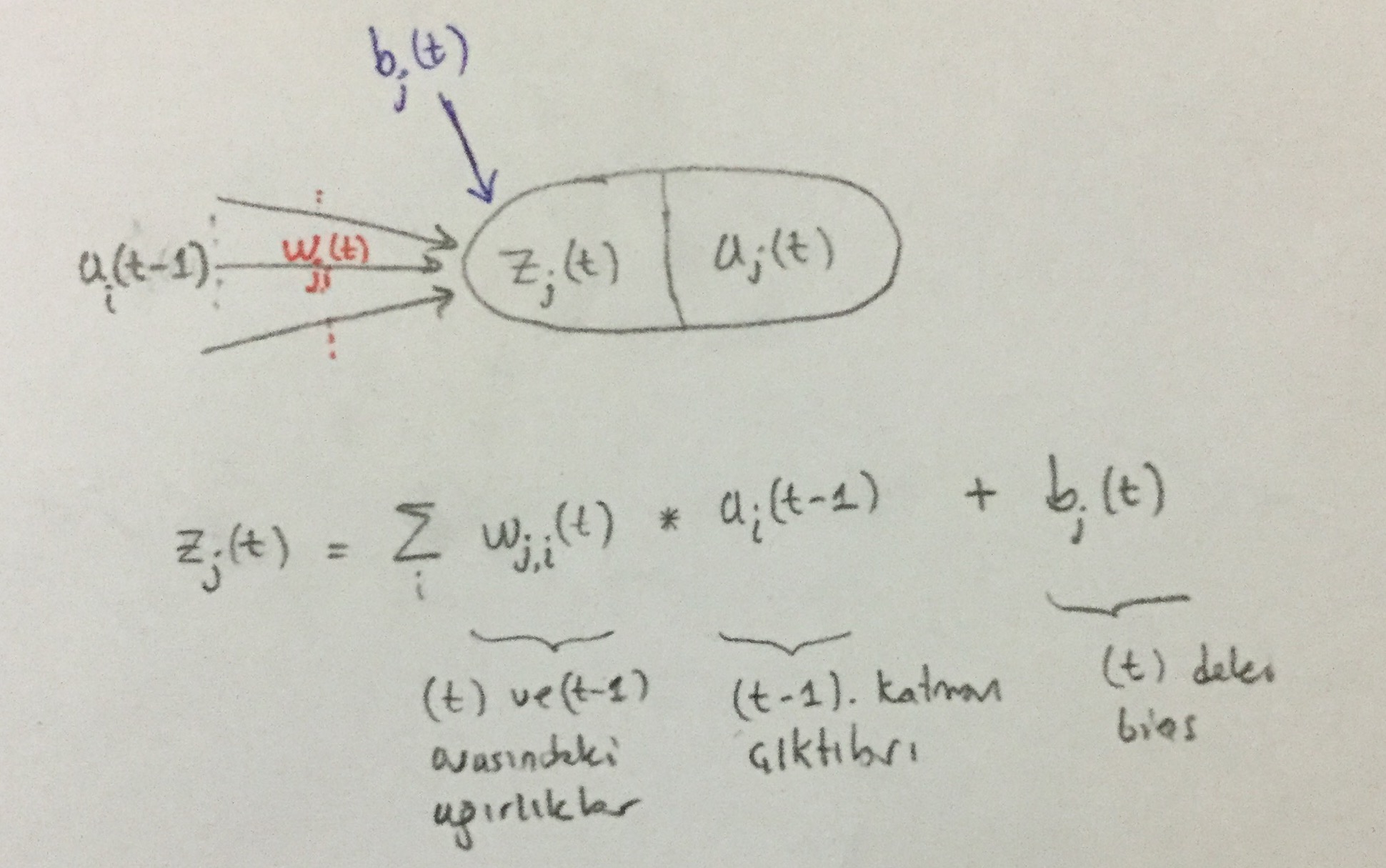
Yukarıdaki yapay sinir ağı, 3 katmandan oluşmaktadır.
Birinci katman, girdi olarak $x_1$, $x_2$, $x_3$ verisini alir.
ilk katmana özel olarak $a_i(1) = z_i(1) = x_i$dir.
Daha sonraki katmanlardaki nöronlar, bir önceki katmanın ağırlıklı toplamını girdi olarak kabul eder.
Genel olarak,
$z_j(t) = \sum_i w_{j,i}(t) \times a_i(t-1) + b_j(t)$
mesela $z_4(2) = w_{4,1}(2) \times a_1(1) + w_{4,2}(2) \times a_2(1) + w_{4,3}(2) \times a_3(1) + b_4(2)$dir.
$w_{j,i}(t)$: $\hspace{1cm}$ $(t-1)$'inci katmandaki $i$'nci nörondan $(t)$'inci katmandaki $j$nci nörona olan bağlantının ağırlık değeridir.
Aynı şekilde
$b_{j}(t)$: $\hspace{1cm}$ $(t)$'inci katmandaki $j$'nci nörona ait bias değeridir
Bir nöronun çıktısı, sigmoid fonksiyonuna net girdi değeri verilerek hesaplanır.
$a_j(t) = \sigma(z_j(t)) = \frac{1}{1 + e^{z_j(t)}}$
İleri Besleme Algoritması¶
Ağımız verilen girdi x ve ağırlık w, bias b değerlerine göre bir çıktı üretir. Vektörize edilerek yapılan işlem
$z(t) = w(t) \cdot a(t-1) + b(t)$
$a(t) = \sigma(z(t))$
Her bir katmandaki nöronlar, önceki katmanlardaki nöron çıktılarını ağırlıklarıyla çarpıp son olarak bias(çapa ya da referans) değeri ekleyerek net girdi olan $z$ değerini bulurlar. Sonraki işlem ise, sigmoid ile çıktı değerini hesaplamaktır.

def ileribesleme(a, agirlik, bias):
"""Katman katman yeni a degerleri hesaplaniyor"""
for w, b in zip(agirlik, bias):
z = np.dot(w, a)+b
a = sigmoid(z)
return a
katmanlar = [2, 3, 1]
agirlik, bias = ag(katmanlar)
girdi = [[0],
[0]]
print(ileribesleme(girdi, agirlik, bias))
Yardımcı Türevler¶
İleri Besleme algortimasına bakarak şu türevleri bulalım, bunlar bize geri besleme algoritmasında yardımcı olacak
$$ \frac{d z_j(t+1)}{d z_i(t)} = \frac{ d (\sum_i w_{j,i}(t+1) \times \sigma(z_i(t)) + b_j(t+1))}{d z_i(t)} = w_{j,i}(t+1) \times \sigma'(z_i(t)) $$

Geri Besleme¶
Geri besleme algoritmasındaki kilit nokta, bir nöronun ait girdideki değişim, hatayı nasıl etkiler sorusudur.
$$ \Delta_j(t) = \frac{d Hata}{d z_j(t)} $$Bu soruya vereceğimiz cevap ile, ağırlık ve bias değerlerini hatayı minimize edecek şekilde nasıl güncelleyeceğimizi bulacağız. Ve tabi gene gradyan iniş yöntemini kullanacağız.
$$Hata = \frac{1}{2} \sum_j (y_j - a_j(T))^2$$$T$ ağdaki çıktı katmanıdır. Bu durumda çıktı katmanındaki j'inci nöronun hataya etkisi
$$ \Delta_j(T) = \frac{d Hata}{d z_j(T)} = \frac{d Hata}{d a_j(T)} \frac{d a_j(T)}{d z_j(T)} = (a_j(T)-y_j ) \frac{d a_j(T)}{d z_j(T)} = (a_j(T)-y_j ) \sigma'(z_j(T)) $$Çıktı katmanındaki tüm nöronların hataya olan etkisini vektörize edersek
$$ \Delta(T) = \frac{d Hata}{d z(T)} = (a(T)-y) \sigma'(z(T)) $$
Dikkat ederseniz, vektörize ettiğimizde indislerden kurtuluyoruz. Peki bir ara katmandan, önceki ara katmana hata nasıl yayılır?
$$ \Delta_i(t) = \frac{d Hata}{d z_i(t)} = \sum_j \frac{d Hata}{d z_j(t+1)} \frac{d z_j(t+1)}{d z_i(t)} = \sum_j \Delta_j(t+1) \frac{d z_j(t+1)}{d z_i(t)} $$
Unutmayın ki, $(t)$'inci katmandaki nöron $i$'ye ait bir hata $(t+1)$'inci katmandaki tüm $j$ nöronlarını etkiler. Sonuç olarak,
$$ \Delta_i(t) = \sum_j \Delta_j(t+1) w_{j,i}(t+1) \times \sigma'(z_i(t)) $$
$(t+1)$'inci katmandan $(t)$'inci katmana hatanın akışını vektörize edersek,
$$ \Delta(t) = w^T(t+1) \cdot \Delta(t+1) \times \sigma'(z(t)) $$
Nöronlardaki hatanın güncellenmesi¶
Çıktı katmanında $$ \Delta(T) = \frac{d Hata}{d z(T)} = (a(T)-y) \sigma'(z(T)) $$
$(t+1)$'inci ara katmandan $(t)$'inci ara katmana hatanın akışı,
$$ \Delta(t) = w^T(t+1) \cdot \Delta(t+1) \times \sigma'(z(t)) $$Ağırlık ve bias değerlerinin güncellenmesi¶
Hatayı minimize eden en iyi parametreleri arıyoruz.
Ağırlıktaki değişim $$ \frac{d Hata}{d w_{ji}(t)} = \frac{d Hata}{d z_{j}(t)} \frac{d z_{j}(t)}{d w_{ji}(t)} = \Delta_{j}(t) a_i(t-1) $$
Biasdeki değişim $$ \frac{d Hata}{d b_{j}(t)} = \frac{d Hata}{d z_{j}(t)} \frac{d z_{j}(t)}{d b_{j}(t)} = \Delta_{j}(t) $$
Geri Besleme algoritması neden hızlıdır?
Dikkat ederseniz $\Delta_{j}(t)$ değerini sadece bir kez hesaplayıp, yeniden hesaplamadan bir çok yerde (Ağırlıktaki ve Biasdeki değişimde) tekrar tekrar kullanıyoruz. Bu bize hız kazandırıyor.

def geribesleme(x,y, agirlik, bias): #girdi, cikti
delta_b = [np.zeros(b.shape) for b in bias]
delta_w = [np.zeros(w.shape) for w in agirlik]
a = x
A = [a] # a degerleri
Z = [] # z degerleri
for w, b in zip(agirlik, bias):# z ve a degerlerini depolayalim
z = np.dot(w, a) + b
a = sigmoid(z)
Z.append(z)
A.append(a)
hata = A[-1] - y # en son katmandaki hata
delta = hata * sigmoid_turevi(Z[-1])
delta_b[-1] = delta
delta_w[-1] = np.dot(delta, A[-2].T)
for k in range(2, len(katmanlar)):
delta = np.dot(agirlik[-k+1].T, delta) * sigmoid_turevi(Z[-k])
delta_b[-k] = delta
delta_w[-k] = np.dot(delta, A[-k-1].T)
return (delta_b, delta_w)
def gradyan_inis(orneklem, adim, agirlik, bias):
delta_b = [np.zeros(b.shape) for b in bias]
delta_w = [np.zeros(w.shape) for w in agirlik]
for x, y in orneklem:
delta_bxy, delta_wxy = geribesleme(x, y, agirlik, bias)
delta_b = [nb+dnb for nb, dnb in zip(delta_b, delta_bxy)]
delta_w = [nw+dnw for nw, dnw in zip(delta_w, delta_wxy)]
agirlik = [w-(adim/len(orneklem))*nw for w, nw in zip(agirlik, delta_w)]
bias = [b-(adim/len(orneklem))*nb for b, nb in zip(bias, delta_b)]
return agirlik, bias
def ogrenme(veri, agirlik, bias, epochs = 30, sayi = 10, adim = 0.5, test_data=None):
""" epochs: kac kez tum veri kullaniacak
icinde sayi kadar ornek bulunan orneklemler(mini-batch)
gradyan-iniste kullaniliyor. Agirlik ve bias degerleri guncelleniyor.
Ogrenme:
en iyi Agirlik ve bias degerelerini bulmak
"""
veri = list(veri)
n = len(veri)
if test_data:
test_data = list(test_data)
n_test = len(test_data)
for j in range(epochs):
random.shuffle(veri)
for orneklem in [veri[k:k+sayi] for k in range(0, n, sayi)]:
agirlik, bias = gradyan_inis(orneklem, adim, agirlik, bias)
if test_data:
print("Epoch {} : {} / {}".format(j, tahmin(test_data, agirlik, bias), n_test));
else:
print("Epoch {} complete".format(j))
def tahmin(test_data, agirlik, bias):
"""Return the number of test inputs for which the neural
network outputs the correct result. Note that the neural
network's output is assumed to be the index of whichever
neuron in the final layer has the highest activation."""
test_results = [(np.argmax(ileribesleme(x, agirlik, bias)), y) for (x, y) in test_data]
return sum(int(x == y) for (x, y) in test_results)
Calisma¶
katmanlar = [2, 3, 1]
agirlik, bias = ag(katmanlar)
veri = []
test = []
ogrenme(veri, agirlik, bias, test_data= test)
import mnist_loader
training_data, validation_data, test_data = mnist_loader.load_data_wrapper()
training_data = list(training_data)
katmanlar = [784, 30, 10]
agirlik, bias = ag(katmanlar)
ogrenme(training_data, agirlik, bias, 3, 10, 3.0, test_data=test_data)
agirlik, bias = gradyan_inis(training_data[1:10],adim = 0.5, agirlik = agirlik, bias = bias)
test_data